The Problem: Your AI Doesn’t Know Your Business
You’ve tried ChatGPT. Maybe you’ve even paid for the API. And it’s impressive — until it confidently tells a customer the wrong return policy, invents a product feature that doesn’t exist, or quotes a pricing tier you
discontinued eight months ago.
This isn’t a bug. It’s a fundamental limitation.
Large language models like GPT-4 are trained on data with a knowledge cutoff. They have no idea what’s in your internal wiki, your support docs, your pricing spreadsheet, or last quarter’s case studies. When they don’t know
something, they don’t say “I don’t know” — they generate a plausible-sounding answer. That’s hallucination, and in a business context, it’s a liability.
The solution isn’t a better prompt. It’s a different architecture. That architecture is called RAG — and when you add an agentic layer on top, it becomes one of the most powerful tools a UK startup can deploy right now.
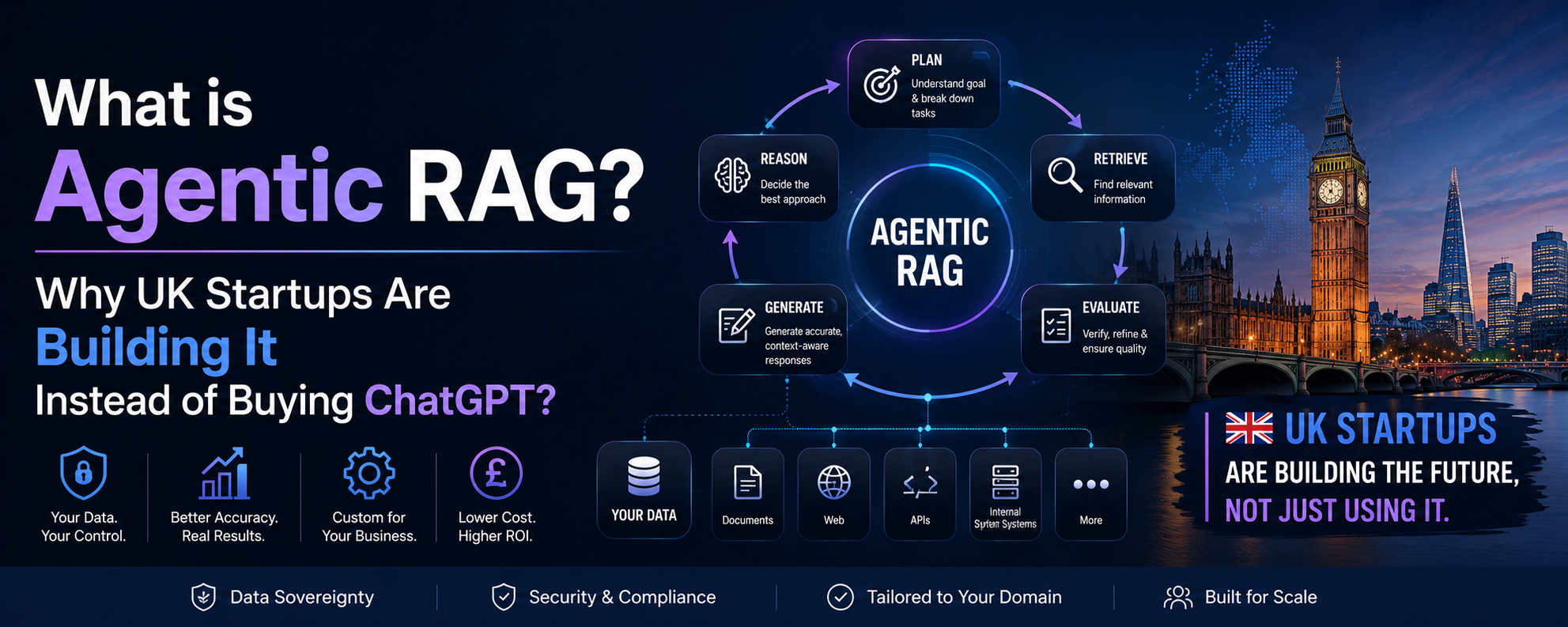
What Is RAG? (The Plain-English Version)
RAG stands for Retrieval-Augmented Generation. Before the AI generates any response, it first retrieves relevant information from your own knowledge base — your documents, your database, your product data — and uses that as
context.
Think of it like this: instead of asking a smart stranger what your refund policy is, you hand them your actual policy document and ask them to explain it. The answer is grounded in real, current, company-specific information —
not a best guess.
The retrieval step works by converting your documents into vector embeddings, storing them in a vector database, and at query time finding the chunks most semantically similar to the user’s question. Those chunks are handed to
the LLM alongside the question, and the LLM synthesises a coherent, accurate response.
What Does “Agentic” Add?
Standard RAG is a single retrieval step. Agentic RAG reasons about what to retrieve, decides whether the first retrieval was sufficient, and chains multiple retrieval and reasoning steps autonomously before responding:
- Breaks down complex multi-part questions and retrieves different sources for each
- Reformulates search queries if confidence is low
- Cross-references multiple knowledge bases (product catalogue + pricing doc)
- Calls external tools — APIs, databases, calendars — not just static documents
Three UK SME Use Cases — With Real Numbers
Customer Support — £4,200/month saved
58% of tickets resolved without human touch. Resolution time for escalated tickets: 47 min → 19 min.
Employee Onboarding — 3 weeks → 11 days
Senior staff interruptions for process questions fell 71%. System flagged 23 outdated documents as a side benefit.
Finance & Compliance Q&A — 2.3 hrs → 14 minutes
Zero compliance errors in six months post-deployment. Full audit trail via citation logging.
Cost and Timeline for Building Agentic RAG
The cost of building an Agentic RAG system depends on the complexity of the workflows, the number of data sources, integration requirements, and the level of production readiness needed.
| Scope | Estimated Cost | Estimated Timeline |
|---|---|---|
| Minimal viable RAG | £8,000 – £15,000 | 3 – 5 weeks |
| Production agentic RAG | £25,000 – £60,000 | 8 – 16 weeks |
| Monthly operations, API and hosting | £200 – £800 per month | Ongoing |
A minimal viable RAG system is usually suitable for testing the concept, validating business use cases, and building an internal prototype. A production-grade agentic RAG system requires more advanced planning, including workflow orchestration, security controls, monitoring, evaluation, guardrails, integrations, and ongoing optimisation.
Monthly operational costs typically include LLM API usage, vector database hosting, cloud infrastructure, monitoring tools, storage, and maintenance.
Common Mistakes to Avoid When Building a RAG System
Building a RAG system can deliver strong business value, but only when the architecture is designed carefully. Many projects fail not because the LLM is weak, but because the retrieval layer, data pipeline, or governance model is poorly planned.
1. Poor Chunking
Naive document splitting can destroy context. If chunks are too small, the system may miss important meaning. If they are too large, retrieval becomes noisy and less accurate. A good RAG system needs chunking that matches the structure of the source content.
2. Skipping Retrieval Evaluation
Do not only test the final LLM answer. The retriever should be evaluated separately to check whether it is finding the right documents, sections, and evidence before the answer is generated.
3. No Low-Confidence Handling
A RAG system should know when not to answer. When confidence is low or the retrieved context is weak, it is better to say “I don’t have enough information” than to generate a misleading response.
4. Ignoring Data Freshness
Outdated data can lead to incorrect answers. Ingestion pipelines should be planned from day one so that documents, policies, product data, or internal knowledge bases remain current.
5. Over-Engineering Too Early
Adding agentic workflows before validating retrieval can make the system more complex without improving quality. Bad retrieval combined with agentic complexity usually means faster hallucination, not better automation.
6. Underestimating Access Control
Business RAG systems often need role-based filtering, department-level permissions, and secure document access. Access control should be designed early, not added later as an afterthought.
Thinking About Building a RAG System for Your Business?
Book a free discovery call with Webygraphy. We will help you understand whether RAG is the right fit for your business, what type of system you actually need, and how to avoid unnecessary cost or complexity.
Frequently Asked Questions
Q: What is agentic RAG?
An AI system that autonomously decides what to retrieve, from where, and how many times — before generating a grounded response. Chains multiple retrievals and tool calls unlike standard single-step RAG.
Q: What is the difference between RAG and ChatGPT?
ChatGPT has no access to your internal data. RAG connects the AI to your own knowledge base so every answer is grounded in your actual documents, not a public training cutoff.
Q: What is the difference between RAG and agentic RAG?
Standard RAG = one retrieval + one response. Agentic RAG = autonomous multi-step reasoning — reformulates queries, cross-references sources, calls APIs — before responding.
Q: How much does a RAG system cost in the UK?
£8k–£15k for a minimal build (3–5 weeks). £25k–£60k for production agentic RAG (8–16 weeks). £200–£800/month ongoing ops.
Q: How long does it take to build?
2–3 weeks for a proof of concept. 8–16 weeks for production. Biggest variable: data quality.
Q: Is RAG better than fine-tuning?
For business use cases, yes. RAG retrieves from a live knowledge base (instant updates, citable sources). Fine-tuning bakes knowledge into weights — expensive to retrain and can’t cite sources.
Q: Can small businesses use agentic RAG?
Yes. UK SMEs with 10–50 employees are already using it for support, onboarding, and compliance.
Q: What data can a RAG system use?
PDFs, Notion, Confluence, Google Docs, Slack, CRM notes, product catalogues, databases — almost any text-based source.
Q: What is AEO and why does it matter?
Answer Engine Optimisation — structuring content so Google SGE, Bing Copilot, and voice assistants surface and cite it directly. FAQs are the core building block.
Q: How do I know if RAG is right for my business?
If accuracy matters, you have proprietary internal data, or off-the-shelf AI keeps hallucinating about your products/policies — RAG is likely the right fit.